之前我们提到,为了保证Redis的高可用,主要需要以下几个方面:
- 数据持久化
- 主从复制
- 自动故障恢复
- 集群化
我们简单理一下这几个方案的特点,以及它们之间的联系。
数据持久化本质上是为了做数据备份,有了数据持久化,当Redis宕机时,我们可以把数据从磁盘上恢复回来,但在数据恢复之前,服务是不可用的,而且数据恢复的时间取决于实例的大小,数据量越大,恢复起来越慢。Redis的持久化过程可以参考Redis持久化是如何做的?RDB和AOF对比分析。
而主从复制则是部署多个副本节点,多个副本节点实时复制主节点的数据,当主节点宕机时,我们有完整的副本节点可以使用。另一方面,如果我们业务的读请求量很大,主节点无法承受所有的读请求,多个副本节点可以分担读请求,实现读写分离,这样可以提高Redis的访问性能。Redis主从复制的原理可以参考Redis的主从复制是如何做的?复制过程中也会产生各种问题?。
但有个问题是,当主节点宕机时,我们虽然有完整的副本节点,但需要手动操作把从节点提升为主节点继续提供服务,如果每次主节点故障,都需要人工操作,这个过程既耗时耗力,也无法保证及时性,高可用的程度将大打折扣。如何优化呢?
此时我们就需要有自动故障恢复机制,当主节点故障时,可以自动把从节点提上来,这个过程是完全自动化的,无需人工干预,这样才能最大程度保证服务的可用性,降低不可用时间。Redis的故障自动恢复是通过哨兵实现的,具体的故障恢复原理,可以参考Redis如何实现故障自动恢复?浅析哨兵的工作原理。
有了数据持久化、主从复制、故障自动恢复这些功能,我们在使用Redis时是不是就可以高枕无忧了?
答案是否定的,如果我们的业务大部分都是读请求,可以使用读写分离提升性能。但如果写请求量也很大呢?现在是大数据时代,像阿里、腾讯这些大体量的公司,每时每刻都拥有非常大的写入量,此时如果只有一个主节点是无法承受的,那如何处理呢?
这就需要集群化!简单来说实现方式就是,多个主从节点构成一个集群,每个节点存储一部分数据,这样写请求也可以分散到多个主节点上,解决写压力大的问题。同时,集群化可以在节点容量不足和性能不够时,动态增加新的节点,对进群进行扩容,提升性能。
从这篇文章开始,我们就开始介绍Redis的集群化方案。当然,集群化也意味着Redis部署架构更复杂,管理和维护起来成本也更高。而且在使用过程中,也会遇到很多问题,这也衍生出了不同的集群化解决方案,它们的侧重点各不相同。
这篇文章我们先来整体介绍一下Redis集群化比较流行的几个解决方案,先对它们有整体的认识,后面我会专门针对我比较熟悉的集群方案进行详细的分析。
集群化方案
要想实现集群化,就必须部署多个主节点,每个主节点还有可能有多个从节点,以这样的部署结构组成的集群,才能更好地承担更大的流量请求和存储更多的数据。
可以承担更大的流量是集群最基础的功能,一般集群化方案还包括了上面提到了数据持久化、数据复制、故障自动恢复功能,利用这些技术,来保证集群的高性能和高可用。
另外,优秀的集群化方案还实现了在线水平扩容功能,当节点数量不够时,可以动态增加新的节点来提升整个集群的性能,而且这个过程是在线完成的,业务无感知。
业界主流的Redis集群化方案主要包括以下几个:
- 客户端分片
- Codis
- Twemproxy
- Redis Cluster
它们还可以用是否中心化来划分,其中客户端分片、Redis Cluster属于无中心化的集群方案,Codis、Tweproxy属于中心化的集群方案。
是否中心化是指客户端访问多个Redis节点时,是直接访问还是通过一个中间层Proxy来进行操作,直接访问的就属于无中心化的方案,通过中间层Proxy访问的就属于中心化的方案,它们有各自的优劣,下面分别来介绍。
客户端分片
客户端分片主要是说,我们只需要部署多个Redis节点,具体如何使用这些节点,主要工作在客户端。
客户端通过固定的Hash算法,针对不同的key计算对应的Hash值,然后对不同的Redis节点进行读写。
客户端分片需要业务开发人员事先评估业务的请求量和数据量,然后让DBA部署足够的节点交给开发人员使用即可。
这个方案的优点是部署非常方便,业务需要多少个节点DBA直接部署交付即可,剩下的事情就需要业务开发人员根据节点数量来编写key的请求路由逻辑,制定一个规则,一般采用固定的Hash算法,把不同的key写入到不同的节点上,然后再根据这个规则进行数据读取。
可见,它的缺点是业务开发人员使用Redis的成本较高,需要编写路由规则的代码来使用多个节点,而且如果事先对业务的数据量评估不准确,后期的扩容和迁移成本非常高,因为节点数量发生变更后,Hash算法对应的节点也就不再是之前的节点了。
所以后来又衍生出了一致性哈希算法,就是为了解决当节点数量变更时,尽量减少数据的迁移和性能问题。
这种客户端分片的方案一般用于业务数据量比较稳定,后期不会有大幅度增长的业务场景下使用,只需要前期评估好业务数据量即可。
Codis
随着业务和技术的发展,人们越发觉得,当我需要使用Redis时,我们不想关心集群后面有多少个节点,我们希望我们使用的Redis是一个大集群,当我们的业务量增加时,这个大集群可以增加新的节点来解决容量不够用和性能问题。
这种方式就是服务端分片方案,客户端不需要关心集群后面有多少个Redis节点,只需要像使用一个Redis的方式去操作这个集群,这种方案将大大降低开发人员的使用成本,开发人员可以只需要关注业务逻辑即可,不需要关心Redis的资源问题。
多个节点组成的集群,如何让开发人员像操作一个Redis时那样来使用呢?这就涉及到多个节点是如何组织起来提供服务的,一般我们会在客户端和服务端中间增加一个代理层,客户端只需要操作这个代理层,代理层实现了具体的请求转发规则,然后转发请求到后面的多个节点上,因此这种方式也叫做中心化方式的集群方案,Codis就是以这种方式实现的集群化方案。
Codis是由国人前豌豆荚大神开发的,采用中心化方式的集群方案。因为需要代理层Proxy来进行所有请求的转发,所以对Proxy的性能要求很高,Codis采用Go语言开发,兼容了开发效率和性能。
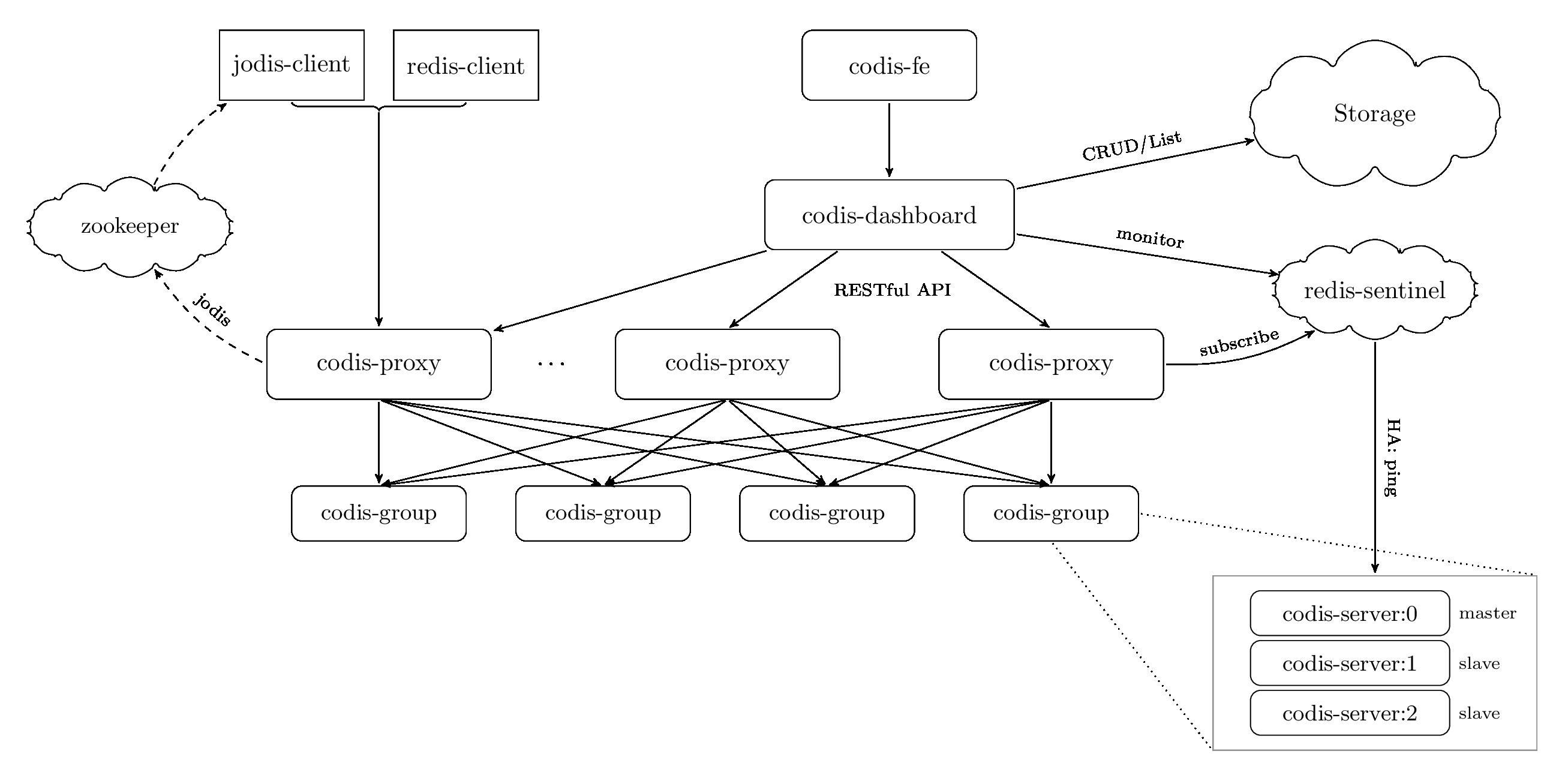
Codis包含了多个组件:
- codis-proxy:主要负责对请求的读写进行转发
- codis-dashbaord:统一的控制中心,整合了数据转发规则、故障自动恢复、数据在线迁移、节点扩容缩容、自动化运维API等功能
- codis-group:基于Redis 3.2.8版本二次开发的Redis Server,增加了异步数据迁移功能
- codis-fe:管理多个集群的UI界面
可见Codis的组件还是挺多的,它的功能非常全,除了请求转发功能之外,还实现了在线数据迁移、节点扩容缩容、故障自动恢复等功能。
Codis的Proxy就是负责请求转发的组件,它内部维护了请求转发的具体规则,Codis把整个集群划分为1024个槽位,在处理读写请求时,采用crc32Hash算法计算key的Hash值,然后再根据Hash值对1024个槽位取模,最终找到具体的Redis节点。
Codis最大的特点就是可以在线扩容,在扩容期间不影响客户端的访问,也就是不需要停机。这对业务使用方是极大的便利,当集群性能不够时,就可以动态增加节点来提升集群的性能。
为了实现在线扩容,保证数据在迁移过程中还有可靠的性能,Codis针对Redis进行了修改,增加了针对异步迁移数据相关命令,它基于Redis 3.2.8进行开发,上层配合Dashboard和Proxy组件,完成对业务无损的数据迁移和扩容功能。
因此,要想使用Codis,必须使用它内置的Redis,这也就意味着Codis中的Redis是否能跟上官方最新版的功能特性,可能无法得到保障,这取决于Codis的维护方,目前Codis已经不再维护,所以使用Codis时只能使用3.2.8版的Redis,这是一个痛点。
另外,由于集群化都需要部署多个节点,因此操作集群并不能完全像操作单个Redis一样实现所有功能,主要是对于操作多个节点可能产生问题的命令进行了禁用或限制,具体可参考Codis不支持的命令列表。
但这不影响它是一个优秀的集群化方案,由于我司使用Redis集群方案较早,那时Redis Cluster还不够成熟,所以我司使用的Redis集群方案就是Codis。目前我的工作主要是围绕Codis展开的,我们公司对Codis进行了定制开发,还对Redis进行了一些改造,让Codis支持了跨多个数据中心的数据同步,因此我对Codis的代码比较熟悉,后面会专门写一些文章来剖析Codis的实现原理,学习它的原理,这对我们理解分布式存储有很大的帮助!
Twemproxy
Twemproxy是由Twitter开源的集群化方案,它既可以做Redis Proxy,还可以做Memcached Proxy。
它的功能比较单一,只实现了请求路由转发,没有像Codis那么全面有在线扩容的功能,它解决的重点就是把客户端分片的逻辑统一放到了Proxy层而已,其他功能没有做任何处理。
Tweproxy推出的时间最久,在早期没有好的服务端分片集群方案时,应用范围很广,而且性能也极其稳定。
但它的痛点就是无法在线扩容、缩容,这就导致运维非常不方便,而且也没有友好的运维UI可以使用。Codis就是因为在这种背景下才衍生出来的。
Redis Cluster
采用中间加一层Proxy的中心化模式时,这就对Proxy的要求很高,因为它一旦出现故障,那么操作这个Proxy的所有客户端都无法处理,要想实现Proxy的高可用,还需要另外的机制来实现,例如Keepalive。
而且增加一层Proxy进行转发,必然会有一定的性能损耗,那么除了客户端分片和上面提到的中心化的方案之外,还有比较好的解决方案么?
Redis官方推出的Redis Cluster另辟蹊径,它没有采用中心化模式的Proxy方案,而是把请求转发逻辑一部分放在客户端,一部分放在了服务端,它们之间互相配合完成请求的处理。
Redis Cluster是在Redis 3.0推出的,早起的Redis Cluster由于没有经过严格的测试和生产验证,所以并没有广泛推广开来。也正是在这样的背景下,业界衍生了出了上面所说的中心化集群方案:Codis和Tweproxy。
但随着Redis的版本迭代,Redis官方的Cluster也越来越稳定,更多人开始采用官方的集群化方案。也正是因为它是官方推出的,所以它的持续维护性可以得到保障,这就比那些第三方的开源方案更有优势。
Redis Cluster没有了中间的Proxy代理层,那么是如何进行请求的转发呢?
Redis把请求转发的逻辑放在了Smart Client中,要想使用Redis Cluster,必须升级Client SDK,这个SDK中内置了请求转发的逻辑,所以业务开发人员同样不需要自己编写转发规则,Redis Cluster采用16384个槽位进行路由规则的转发。
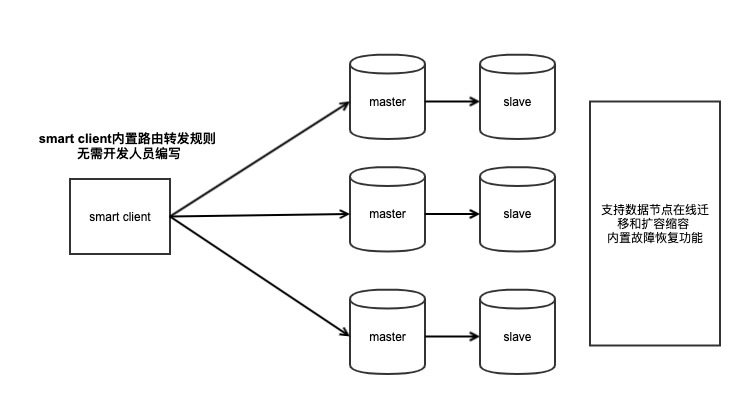
没有了Proxy层进行转发,客户端可以直接操作对应的Redis节点,这样就少了Proxy层转发的性能损耗。
Redis Cluster也提供了在线数据迁移、节点扩容缩容等功能,内部还内置了哨兵完成故障自动恢复功能,可见它是一个集成所有功能于一体的Cluster。因此它在部署时非常简单,不需要部署过多的组件,对于运维极其友好。
Redis Cluster在节点数据迁移、扩容缩容时,对于客户端的请求处理也做了相应的处理。当客户端访问的数据正好在迁移过程中时,服务端与客户端制定了一些协议,来告知客户端去正确的节点上访问,帮助客户端订正自己的路由规则。
虽然Redis Cluster提供了在线数据迁移的功能,但它的迁移性能并不高,迁移过程中遇到大key时还有可能长时间阻塞迁移的两个节点,这个功能相较于Codis来说,Codis数据迁移性能更好。这里先了解一个大概就好,后面我会专门针对Codis和Redis Cluster在线迁移功能的性能对比写一些文章。
现在越来越多的公司开始采用Redis Cluster,有能力的公司还在它的基础上进行了二次开发和定制,来解决Redis Cluster存在的一些问题,我们期待Redis Cluster未来有更好的发展。
总结
比较完了这些集群化方案,下面我们来总结一下。
| # | 客户端分片 | Codis | Tweproxy | Redis Cluster |
|---|---|---|---|---|
| 集群模式 | 无中心化 | 中心化 | 中心化 | 无中心化 |
| 使用方式 | 客户端编写路由规则代码,直连Redis | 通过Proxy访问 | 通过Proxy访问 | 使用Smart Client直连Redis,Smart Client内置路由规则 |
| 性能 | 高 | 有性能损耗 | 有性能损耗 | 高 |
| 支持的数据库数量 | 多个 | 多个 | 多个 | 一个 |
| Pipeline | 支持 | 支持 | 支持 | 仅支持单个节点Pipeline,不支持跨节点 |
| 需升级客户端SDK? | 否 | 否 | 否 | 是 |
| 支持在线水平扩容? | 不支持 | 支持 | 不支持 | 支持 |
| Redis版本 | 支持最新版 | 仅支持3.2.8,升级困难 | 支持最新版 | 支持最新版 |
| 可维护性 | 运维简单,开发人员使用成本高 | 组件较多,部署复杂 | 只有Proxy组件,部署简单 | 运维简单,官方持续维护 |
| 故障自动恢复 | 需部署哨兵 | 需部署哨兵 | 需部署哨兵 | 内置哨兵逻辑,无需额外部署 |
业界主流的集群化方案就是以上这些,并对它们的特点和区别做了简单的介绍,我们在开发过程中选择自己合适的集群方案即可,但最好是理解它们的实现原理,在使用过程中遇到问题才可以更从容地去解决。

