你好,我是 Kaito。
上次聊了下我来腾讯一年多的感受,很多读者对我的职业经历比较好奇,那么这篇就重点来聊一聊我近 10 年的工作经历。
这篇会详细阐述我从毕业到现在,是如何从一名业务开发,慢慢走向基础架构方向的。以及在这期间我面临的选择和思考,希望对你也有所启发。
你好,我是 Kaito。
上次聊了下我来腾讯一年多的感受,很多读者对我的职业经历比较好奇,那么这篇就重点来聊一聊我近 10 年的工作经历。
这篇会详细阐述我从毕业到现在,是如何从一名业务开发,慢慢走向基础架构方向的。以及在这期间我面临的选择和思考,希望对你也有所启发。
你好,我是 Kaito。
很多关注我比较早的读者都知道,我的公众号(二维码在文末)去年断更了一年,原因是因为去年换了工作来到了腾讯,因为工作方向也发生了一些变化,从舒适区跨入陌生领域,所以更多时间花在了工作上,当时无奈公众号更新只能暂时搁置。
上周在公众号也发了个通知,最近又换了新工区了(搬到了腾讯北京总部大楼),算了一下,来腾讯已经一年多了,借这个机会写篇文章记录下这一年来的感受吧。
你好,我是 Kaito。
这篇我们不聊技术,聊一聊读书。
这个公众号除了聊技术之外,也会不定期写一些我最近的思考和感悟,一般会涉及商业、科技、数码产品、个人成长领域,希望我的思考对你有些许帮助。
最近读了一本书《火星人马斯克的地球创业游戏》,讲马斯克的书市面上很多,这本是中国人写的,豆瓣评分还不错,7.2 分。
你好,我是 Kaito。
好久不见,2022 年已经过去半个月,由于最近事情比较多,拖到现在才写自己的 2021 总结。
之前每到年终时,我都是在朋友圈发一个简单的总结,因为去年开通了公众号,那么从今年开始,每年的年终总结都会写我的个人公众号 + 技术博客上,详细记录一下每年的事情和思考。(文末扫码关注我的公众号)
2021 年对我来说,可以算得上是变化最大的一年了,这一年做出了一点小成绩,也有了一些新的思考,记录下来希望对你也有所启发。
你好,我是 Kaito。
上周五,我在极客时间做了一场直播,也是我有史以来第一次公开直播,从忐忑的心情到把它完成,整个经历还挺有意思的。
写下这篇文章和你聊一聊这段经历,以及在这过程中我的一些启发和思考,希望对你也有所帮助。
你好,我是 Kaito。
今天我想和你聊一聊优秀程序员的基本素养。
我想你肯定遇到过这样一类程序员:他们无论是写代码,还是写文档,又或是和别人沟通,都显得特别专业。每次遇到这类人,我都在想,他们到底是怎么做到的?
随着工作时间的增长,渐渐地我也总结出一些经验,他们身上都保持着一些看似很微小的优秀习惯,但正是因为这些习惯,体现出了一个优秀程序员的基本素养。
但今天我们来换个角度,来看看一个糟糕程序员有哪些坏习惯?只要我们都能避开这些问题,就可以逐渐向一个优秀程序员靠近。
你好,我是 Kaito。
上个月苹果发布会上,对于新款 MacBook 只字未提,本以为今年 MacBook 产品线更新无望了,没想到 10 月又专门安排了一场发布会。
这次,终于发布了万众期待的新款 MacBook Pro。
我又看了全程直播,和你同步一下最新动态。
看完整场发布会,整体感受就像苹果宣传语所描述,2 个字:炸场。
这场发布会一共发布了:
你好,我是 Kaito。
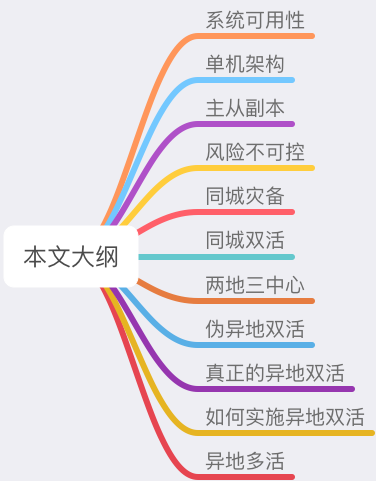
在软件开发领域,「异地多活」是分布式系统架构设计的一座高峰,很多人经常听过它,但很少人理解其中的原理。
异地多活到底是什么?为什么需要异地多活?它到底解决了什么问题?究竟是怎么解决的?
这些疑问,想必是每个程序看到异地多活这个名词时,都想要搞明白的问题。
有幸,我曾经深度参与过一个中等互联网公司,建设异地多活系统的设计与实施过程。所以今天,我就来和你聊一聊异地多活背后的的实现原理。
认真读完这篇文章,我相信你会对异地多活架构,有更加深刻的理解。
这篇文章干货很多,希望你可以耐心读完。
你好,我是 Kaito。
国庆假期,你是在外面游玩,还是在宅在家里呢?今天我们来聊一聊电影吧。
每逢国庆节假日,都会有新的电影上映,我是一个妥妥的电影迷,每逢遇到好的电影上映,都会第一时间跑去电影院,平时一年下来看过的电影在 40 部以上了。
你好,我是 Kaito。
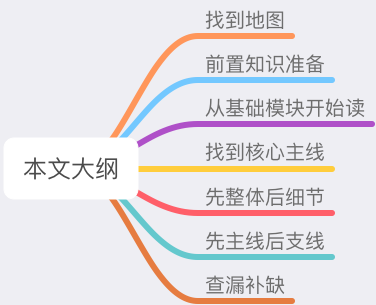
用了这么久的 Redis,也翻了很多次源码,经常有人问我到底怎么读 Redis 源码。
一提到读源码,很多人都会比较畏惧,认为读源码是高手才会做的事情。他们可能遇到问题时,会更倾向于去找别人分享的答案。但往往很多时候,自己查到的资料并不能解决所有问题,尤其是比较细节的问题。
从我的实战经验来看,遇到这种情况,通常就需要去源码中寻找答案了,因为在源码面前,这些细节会变得「一览无余」。
而且我认为,掌握读源码的能力,是从只懂得如何使用 Redis,到精通 Redis 实现原理的成长之路上,必须跨越的门槛。
可是,面对庞大复杂的项目,我们怎样读源码才能更高效呢?
这篇文章我就来和你聊一聊,我读 Redis 源码的经验,以及读源码的「通用思路」,希望这些心得可以帮助到你。