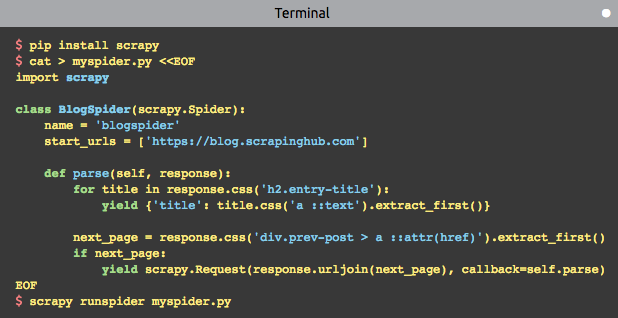
在 Python 开发中,我们经常会看到使用装饰器的场景,例如日志记录、权限校验、本地缓存等等。
使用这些装饰器,给我们的开发带来了极大的便利,那么一个装饰器是如何实现的呢?
这篇文章我们就来分析一下,Python 装饰器的使用及原理。
一切皆对象 在介绍装饰器前,我们需要理解一个概念:在 Python 开发中,一切皆对象 。
什么意思呢?
就是我们在开发中,无论是定义的变量(数字、字符串、元组、列表、字典)、还是方法、类、实例、模块,这些都可以称作对象 。
怎么理解呢?在 Python 中,所有的对象都会有属性和方法,也就是说可以通过「.」去获取它的属性或调用它的方法,例如像下面这样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 i = 10 print id(i), type(i)s = 'hello' print id(s), type(s), s.index('o' )d = {'k' : 10 } print id(d), type(d), d.get('k' )def hello () : print 'Hello World' print id(hello), type(hello), hello.func_name, hello()hello2 = hello print id(hello2), type(hello2), hello2.func_name, hello2()class Person (object) : def __init__ (self, name) : self.name = name def say (self) : return 'I am %s' % self.name print id(Person), type(Person), Person.sayperson = Person('tom' ) print id(person), type(person),print person.name, person.say, person.say()
我们可以看到,常见的这些类型:int、str、dict、function,甚至 class、instance 都可以调用 id 和 type 获得对象的唯一标识和类型。
例如方法的类型是 function,类的类型是 type,并且这些对象都是可传递的。
对象可传递会带来什么好处呢?
这么做的好处就是,我们可以实现一个「闭包」,而「闭包」就是实现一个装饰器的基础。
闭包 假设我们现在想统计一个方法的执行时间,通常实现的逻辑如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import timedef hello () : start = time.time() time.sleep(1 ) print 'hello' end = time.time() print 'duration time: %ds' % int(end - start) hello()
统计一个方法执行时间的逻辑很简单,只需要在调用这个方法的前后,增加时间的记录就可以了。
但是,统计这一个方法的执行时间这么写一次还好,如果我们想统计任意一个方法的执行时间,每个方法都这么写,就会有大量的重复代码,而且不宜维护。
如何解决?这时我们通常会想到,可以把这个逻辑抽离出来:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import timedef timeit (func) : start = time.time() func() end = time.time() print 'duration time: %ds' % int(end - start) def hello () : time.sleep(1 ) print 'hello' timeit(hello)
这里我们定义了一个 timeit 方法,而参数传入一个方法对象,在执行完真正的方法逻辑后,计算其运行时间。
这样,如果我们想计算哪个方法的执行时间,都按照此方式调用即可。
1 2 timeit(func1) timeit(func2)
虽然此方式可以满足我们的需求,但有没有觉得,本来我们想要执行的是 hello 方法,现在执行都需要使用 timeit 然后传入 hello 才能达到要求,有没有一种方式,既可以给原来的方法加上计算时间的逻辑,还能像调用原方法一样使用呢?
答案当然是可以的,我们对 timeit 进行改造:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import timedef timeit (func) : def inner () : start = time.time() func() end = time.time() print 'duration time: %ds' % int(end - start) return inner def hello () : time.sleep(1 ) print 'hello' hello = timeit(hello) hello()
请注意观察 timeit 的变动,它在内部定义了一个 inner 方法,此方法内部的实现与之前类似,但是,timeit 最终返回的不是一个值,而是 inner 对象。
所以当我们调用 hello = timeit(hello) 时,会得到一个方法对象,那么变量 hello 其实是 inner,在执行 hello() 时,真正执行的是 inner 方法。
我们对 hello 方法进行了重新定义,这么一来,hello 不仅保留了其原有的逻辑,而且还增加了计算方法执行耗时的新功能。
回过头来,我们分析一下 timeit 这个方法是如何运行的?
在 Python 中允许在一个方法中嵌套另一个方法,这种特殊的机制就叫做「闭包」 ,这个内部方法可以保留外部方法的作用域,尽管外部方法不是全局的,内部方法也可以访问到外部方法的参数和变量。
装饰器 明白了闭包的工作机制后,那么实现一个装饰器就变得非常简单了。
Python 支持一种装饰器语法糖「@」,使用这个语法糖,我们也可以实现与上面完全相同的功能:
1 2 3 4 5 6 7 8 @timeit # 相当于 hello = timeit(hello) def hello () : time.sleep(1 ) print 'hello' hello()
看到这里,是不是觉得很简单?
这里的 @timeit 其实就等价于 hello = timeit(hello)。
装饰器本质上就是实现一个闭包,把一个方法对象当做参数,传入到另一个方法中,然后这个方法返回了一个增强功能的方法对象。
这就是装饰器的核心,平时我们开发中常见的装饰器,无非就是这种形式的变形而已。